- Published on
Scaling ETLs and Performance Tuning Using AWS Lambda + Kinesis (Part 1 kinesis)
- Authors

- Name
- Younes ZADI
Using Amazon Kinesis alongside AWS Lambda is a powerful combination for scaling an ETL (Extract, Transform, Load) pipeline, especially for real-time data processing. Here’s why this approach is so effective:
- Real-Time Processing: Kinesis can ingest high-volume data streams in real-time.
- Auto-Scaling: Lambda scales automatically with data flow, minimizing management overhead.
- Serverless: With no dedicated servers, this setup saves on infrastructure resources.
- Resilience: Built-in retries and fault tolerance ensure reliable processing.
- Flexibility: Decoupled architecture allows easy ETL layer updates.
- Cost-Effective: Lambda’s pay-per-use model minimizes cost.
- AWS Integration: Easily connects with S3, Redshift, and other AWS services for storage and analytics.
Kinesis Overview
AWS Kinesis is a real-time data streaming service that enables you to collect, process, and analyze large streams of data. For those familiar with Kafka, Kinesis offers similar functionality within the AWS ecosystem.
Kinesis supports a virtually unlimited number of producers for data ingestion and consumers for data processing.
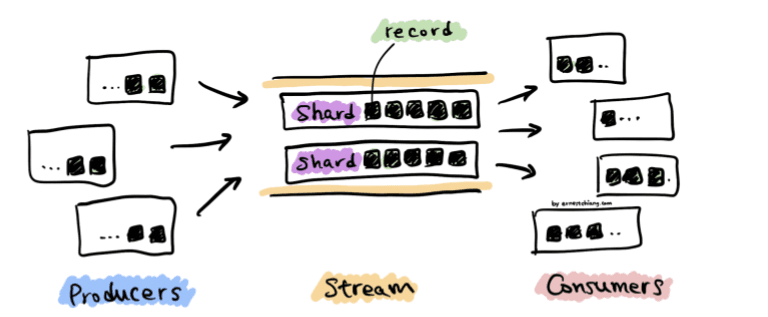
Key Concepts in Kinesis
Record Size: Each record can be up to 1 MB.
Shards: Streams can be divided into shards, which allow you to scale by adjusting the number of shards based on data volume. Each shard can handle up to 1 MB per second and 1,000 records per second for writes, and can read up to 2 MB per second.
Retention Period: Data within a shard has a retention period, defining how long records are stored in the stream. By default, retention is 24 hours but can be extended up to 7 days (or up to 365 days with extended retention). This allows consumers to re-read and process data within this period.
For critical tasks, a longer retention period allows reprocessing in case of failures, especially during periods like weekends.
Partition Key: The partition key, a unique identifier for each record, determines which shard will store the record. This ensures records with the same partition key always go to the same shard, supporting ordered processing for those records.
Choosing the right partition key is crucial—if done incorrectly, it may result in some shards being overloaded.
Monitoring Key Metrics
Monitoring Kinesis metrics is essential to detect and troubleshoot bottlenecks. The most important metrics include:
Iterator Age: The delay between when data is added to the stream and when it is read by a consumer.
Read Latency: The time taken between requesting data from a shard and receiving it.
Write Throughput Exceeded: Occurs when the rate of data writes exceeds the shard’s limit (1 MB/s or 1,000 records per second).
PutRecords Throttled: Indicates when PutRecords requests are throttled due to exceeding the shard’s write limits.

Real-Life Scenarios
With this background, let’s walk through a few real-life scenarios, exploring how to interpret metrics and troubleshoot scaling issues.
Scenario 1: Data Loss from High Iterator Age
Configuration:
- Data retention: 1 day
- Shards: 2
Metrics:
- Iterator Age: 86 million ms (about 24 hours)
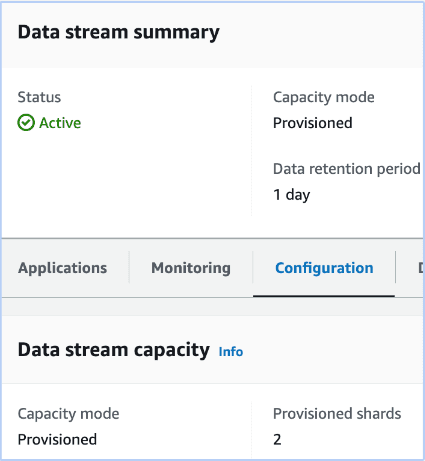
What does this mean? is there an issue? Are we loosing any messages? In this case, the iterator age is close to the data retention period. This suggests that the consumer is not able to keep up with the producer's rate, and messages are indeed being lost.
Solution:
Increasing retention can temporarily prevent message loss, but it’s not a permanent fix. Instead, improve the consumer by optimizing processing logic or increasing shard count to allow for parallel consumption.
Scenario 2: Write Throughput Exceeded
Configuration:
- Data retention: 1 day
- Shards: 2
Metric:
- Write Throughput Exceeded
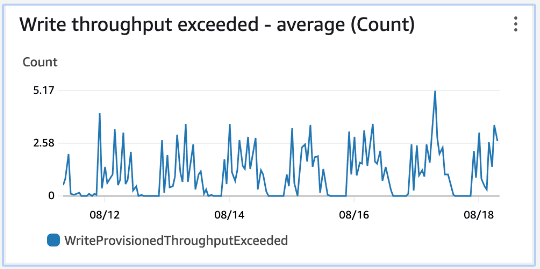
What does it mean ? Will we loose any messages ?
The write throughput being exceeded is related to the producers, not consumers. If you’re using the AWS SDK, retries with exponential backoff will ensure records eventually reach the stream.
Impact on Iterator Age:
This metric does not impact iterator age directly since it’s related to the producer. However, adding more shards can help handle higher write rates.
Scenario 3: Unbalanced Consumer Processing
Configuration:
- Shards: 2
- Consumer setup: Lambda with unreserved concurrency, ECS with 2 tasks
How are the messages consumed from the 2 shards? Will the messages from one shard go to the ECS and messages from the other shard consumed by the lambdas?
In this setup, both Lambda and ECS tasks consume all messages from each shard. For example, if a producer sends message A to shard 1 and message B to shard 2, both Lambda and ECS will consume A and B.
Now let's say we increase the shards to 10 what would happen? would we loose messages?
With 10 shards, Lambda’s concurrent executions will adapt and scale up to 10, but ECS, without autoscaling, will not process the additional shards. This will increase iterator age until the retention period is exceeded, resulting in message loss for ECS.
Scenario 4: High Latency with Maxed Write Limit
Given the following screenshot, what is happening to our system ?
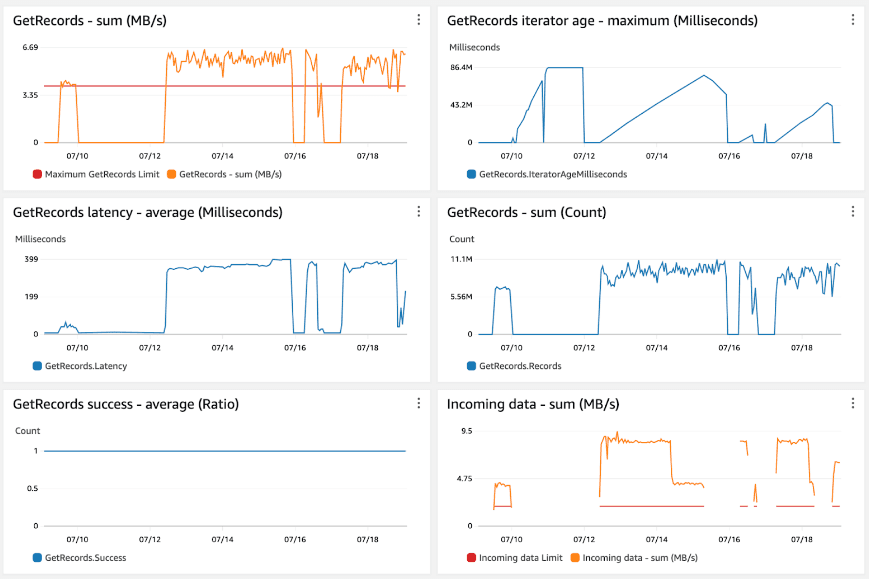
From the incoming data metric we can see incoming data exceeds the shard limit (publisher was writing data at a very high pace).
Also from get records metric, we can deduce that the consumer is reading messages in very high pace, more than we can (the red line represents the max).
In this case the consumer will keep working fine, but it will cause the latency increase. Although AWS manages latency, the increasing iterator age shows the delayed processing of messages
Solution:
To address this, increase the number of shards, enabling greater throughput capacity.
Key Takeaways for Kinesis
- Cost Efficiency: Costs depend on the number of shards, GBs ingested/output, and data retention. Optimize sharding and retention for your use case.
- Monitor Iterator Age: This helps you avoid message loss.
- Customize Sharding: Scale read/write capacity with an appropriate number of shards.
- Occasional Write Throughput Exceeded Warnings: Not a major issue if they’re occasional; AWS SDK retries help manage this.
- Impact of Shard Adjustments on Consumers: Increasing shards may require adjusting consumers as well, such as adding tasks in ECS for workloads without autoscaling.
By understanding these metrics and configurations, you can make informed decisions for scaling and optimizing your ETL pipelines with AWS Lambda and Kinesis.
In part two we will dive deeper into lambdas.